
| Status | Authors | Coach | DRIs | Owning Stage | Created |
|---|---|---|---|---|---|
| ongoing |
@grzesiek
|
@ayufan
@grzesiek
|
@jreporter
@cheryl.li
| devops verify | 2022-05-31 |
- どのような問題を解決しようとしているのか
- CI/CDデータ分解、パーティショニング、時間減衰はどのように関連していますか?
- なぜCI/CDデータをパーティショニングする必要があるのでしょうか?
- CI/CDデータをどのように分割するか?
- なぜ明示的な論理パーティションIDを使用したいのですか?
- パーティショニングされたテーブルの変更
- 大きなパーティションを小さなパーティションに分割
- パーティションのメタデータをデータベースに保存
- パーティショニングを使った時間減衰パターンの実装
- パーティショニングされたデータへのアクセス
- プロジェクトIDまたはネームスペースIDを使用してパーティショニングしてはどうでしょうか?
- パーティショニングはキューイング・テーブルを構築します
- リスクを減らすための反復
- イテレーション
- 結論
- 誰
パイプラインのデータ分割設計
どのような問題を解決しようとしているのか
CI/CDデータセットを分割したいのですが、データベースのテーブルの一部が非常に大きいため、CI/CDデータベースの分割を出荷した後でも、シングルノードの読み込みをスケーリングするのが難しいかもしれません。
PostgreSQLの宣言的パーティショニングを使用して、いくつかの大きなデータベーステーブルを小さなものに変換することで、データベースの性能劣化のリスクを減らしたいのです。
この取り組みの詳細は親ブループリントを参照してください。
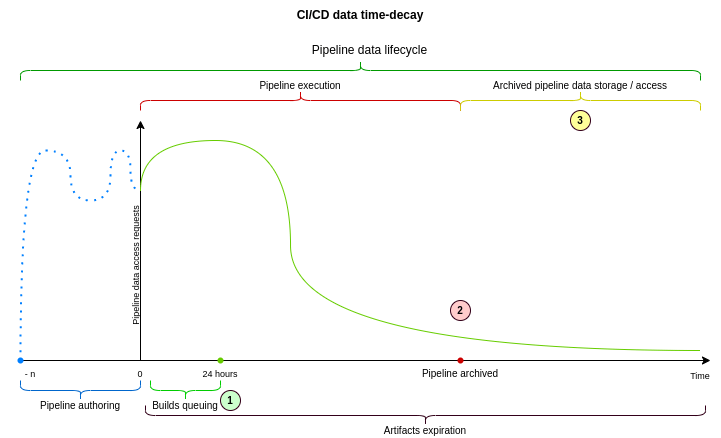
CI/CDデータ分解、パーティショニング、時間減衰はどのように関連していますか?
CI/CDの分解とは、”メイン “データベースクラスタからCI/CDデータベースクラスタを抽出し、書き込みを受けるプライマリデータベースを別のものにすることです。主な利点は、書き込みとデータストレージの容量が2倍になることです。新しいデータベースクラスタは、CI/CDデータベース以外のテーブルの読み取り/書き込みに対応する必要がないため、読み取り用の容量も追加されます。
CI/CDパーティショニングは、大きなCI/CDデータベーステーブルを小さなものに分割します。なぜなら、小さなテーブルからデータを読み込む方が、数テラバイトの大きなテーブルから読み込むよりもはるかに低コストだからです。データを読み込むSQLクエリの増加に対応するためにCI/CDデータベースのレプリカを増やすことはできますが、1回の読み取りをより効率的に実行するためにはパーティショニングが必要です。PostgreSQLは非常に大きなデータベーステーブルを維持するよりも、複数の小さなテーブルを維持する方が効率的であるためです。
CI/CD time-decayにより、パイプラインデータの強い時間減衰特性を利用することができます。これは様々な方法で実装できますが、パーティショニングを使って時間減衰を実装するのは特に有益でしょう。時間減衰を実装する場合、通常はデータをアーカイブとしてマークし、データが関連性がなくなったり必要になったりしたときにデータベースから別の場所にマイグレーションします。私たちのデータセットは非常に大きい(数十テラバイト)ので、このような大量のデータを移行するのは困難です。タイムディケイがパーティショニングを使って実装されている場合、データベーステーブルの1つのレコードを更新するだけで、パーティション(またはパーティションのセット)全体をアーカイブすることができます。これは、データベースレベルで時間崩壊パターンを実装する最も安価な方法の1つです。
なぜCI/CDデータをパーティショニングする必要があるのでしょうか?
CI/CDデータをパーティショニングする必要があるのは、パイプライン、ビルド、アーティファクトを保存しているデータベースのテーブルが大きすぎるからです。ci_builds データベースのテーブルサイズは現在約2.5TBで、インデックスが約1.4GBです。これは大きすぎて、最大サイズ100GBという原則に違反しています。また、この数値を超えたときに通知するアラート機能を構築したいと考えています。
大きなSQLテーブルはインデックスのメンテナンス時間を増加させ、その間に削除されたばかりのタプルをautovacuum 。このため、小さなテーブルの必要性が強調されます。私たちは、巨大なテーブルの(再)インデックス作成時にどれだけの肥大化を蓄積するかを測定します。この分析に基づき、(再)インデックス作成に関連する SLO (デッド・タプル/肥大化)を設定することができます。
ここ数ヶ月の間、S1やS2データベースに関連した本番環境でのインシデントを数多く見てきました:
- S1: 2022-03-17
ci_buildsテーブルへの書き込みの増加 - S1: 2021-11-22レプリカの過剰なバッファリード。
ci_job_artifacts - S2: 2022-04-1210m 以上実行されているトランザクションが検出されました。
- S2: 2022-04-06
ci_buildsの過剰リードが原因と思われるデータベース競合。 - S2: 2022-03-18外部キーの削除ができません。
ci_builds - S2: 2022-10-10
queuing_queries_durationSLIアプデックスがSLOに違反しています。
約50のci_* 接頭辞を持つデータベーステーブルがあり、そのうちのいくつかはパーティショニングの恩恵を受けるでしょう。
このデータを取得する簡単なSQLクエリです:
WITH tables AS (SELECT table_name FROM information_schema.tables WHERE table_name LIKE 'ci_%')
SELECT table_name,
pg_size_pretty(pg_total_relation_size(quote_ident(table_name))) AS total_size,
pg_size_pretty(pg_relation_size(quote_ident(table_name))) AS table_size,
pg_size_pretty(pg_indexes_size(quote_ident(table_name))) AS index_size,
pg_total_relation_size(quote_ident(table_name)) AS total_size_bytes
FROM tables ORDER BY total_size_bytes DESC;
2022年3月のデータをご覧ください:
| 表名 | 合計サイズ | インデックスサイズ |
|---|---|---|
ci_builds | 3.5 TB | 1 TB |
ci_builds_metadata | 1.8 TB | 150 GB |
ci_job_artifacts | 600 GB | 300 GB |
ci_pipelines | 400 GB | 300 GB |
ci_stages | 200 GB | 120 GB |
ci_pipeline_variables | 100 GB | 20 GB |
| (…約40以上) |
上の表から、多くのデータが保存されているテーブルがあることがわかります。
CI/CD関連のデータベーステーブルが50近くありますが、最初はそのうちの6つだけをパーティショニングしたいと考えています。最も興味深いテーブルを反復的にパーティショニングすることから始めることができますが、必要に応じて残りのテーブルをパーティショニングする戦略も持つべきです。このドキュメントは、この戦略を把握し、可能な限り詳細を記述し、エンジニアリングチーム間でこの知識を共有するための試みです。
CI/CDデータをどのように分割するか?
CI/CDテーブルを反復して分割したいのですが。6つの初期テーブルのすべてを一度にパーティショニングすることは現実的ではないかもしれません。また、残りのデータベーステーブルのパーティショニングが必要になった場合の戦略も持っておきたいと考えています。
大規模なデータマイグレーションを避けることも重要です。最大のCI/CDテーブルには6テラバイト近いデータが、さまざまなカラムやインデックスに格納されています。このような量のデータをマイグレーションすることは困難であり、本番環境の不安定化を引き起こす可能性があります。この懸念のため、私たちは、ダウンタイムや過剰なデータベース・ロックを発生させずに、既存のデータベース・テーブルをパーティション・ゼロとしてアタッチする方法を開発しました。これにより、既存のci_pipelines テーブルをパーティション・ゼロとして排他ロックなしでアタッチすることで、ダウンタイムなしでパーティション化されたスキーマを作成することが可能になります(例えば、ルーティング・テーブルp_ci_pipelines を使用)。レガシー・テーブルは通常どおり使用できますが、必要なときに次のパーティションを作成し、p_ci_pipelines テーブルをルーティング・クエリに使用することができます。ルーティング・テーブルを使用するには、適切なパーティショニング・キーを見つける必要があります。
私たちの計画では、論理パーティションIDを使用します。ci_pipelines テーブルから始め、partition_id 列を作成し、DEFAULT 値を100 または1000 とします。DEFAULT 値を使用することで、行ごとにこの値をバックフィルするという課題を回避できます。最初のパーティションをアタッチする前にCHECK 制約を追加することで、PostgreSQLに、このテーブルをパーティションとしてルーティングテーブル(パーティション化されたスキーマ定義)にアタッチする時に、すでに一貫性が確保されており、排他的テーブルロックを保持しながら一貫性を確認する必要がないことを伝えます。p_ci_pipelinesパーティショニング戦略はLIST パーティショニングになります。
また、partition_id 反復的にパーティショニングする他の初期6データベーステーブルにもカラムを partition_id作成します。partition_id 新しいパイプラインが作成されると、そのパイプラインが partition_id割り当てられ、ビルドやアーティファクトなど、関連するすべてのリソースが同じ値を共有します。partition_id カラムを問題のある6つのテーブルすべてに追加したいのは、パーティショニングを開始するときに、このデータを埋め戻さないようにするためです。
CI/CDデータを反復的にパーティショニングしたいのです。ci_builds_metadata これはCIデータベースで最も急速に成長しているテーブルであり、この急激な成長をコンテナで管理したいからです。このテーブルはまた、最も単純なアクセスパターンを持っています。ビルドがRunnerに公開されるときに、このテーブルの行が読み込まれます。p_ci_builds_metadata から始めることで、目に見える定量的な結果を早期に達成することができ、最大のテーブルのパーティショニングを可能にする新しいパターンになるでしょう。私たちは、LIST パーティショニング戦略を使ってビルドのメタデータをパーティショニングします。
p_ci_builds_metadata に多くのパーティションがアタッチされたら、partition_ids 、次にパーティショニングする別のCIテーブルを選びます。RANGE その場合、p_ci_builds_metadata にはすでに多くの物理パーティションがあるため、partition_ids には多くの論理パーティションが使用されることになります。たとえば、p_ci_builds_metadata をパーティショニングした後、次のパーティショニング候補としてci_builds を選択すると、ci_builds.partition_idに多くの異なる値が格納されます。その場合、RANGE パーティショニングを使用する方が簡単かもしれません。
物理パーティショニングと論理パーティショニングは分離され、それぞれのデータベーステーブルに物理パーティショニングを実装するときに戦略が決定されます。RANGE パーティショニングを使用すると、データベース・テーブルでLIST パーティショニングを使用するのと同じように動作しますが、partition_id 値の連続性を保証できるため、RANGE パーティショニングを使用する方が良い戦略かもしれません。
複数プロジェクトのパイプライン
子パイプラインは親パイプラインのリソースとみなされるため、親子パイプラインは常に同じパーティションに属します。子パイプラインは親パイプラインのリソースとみなされるため、親パイプラインと子パイプラインは常に同じパーティションに属します。プロジェクトパイプラインリストページでは、子パイプラインを個別に表示することはできません。
一方、マルチプロジェクトパイプラインは、パイプライン一覧ページで表示できます。また、trigger トークンまたはジョブ トークンを使用した API で作成した場合、パイプライン グラフからダウンストリーム/アップストリーム リンクとしてアクセストークンにアクセスできます。また、トリガートークンを使用して他のパイプラインから作成することもできますが、この場合、ソースパイプラインは保存されません。
ci_builds をパーティショニングする際、ci_sources_pipelines テーブルの外部キーを更新する必要があります:
Foreign-key constraints:
"fk_be5624bf37" FOREIGN KEY (source_job_id) REFERENCES ci_builds(id) ON DELETE CASCADE
"fk_d4e29af7d7" FOREIGN KEY (source_pipeline_id) REFERENCES ci_pipelines(id) ON DELETE CASCADE
"fk_e1bad85861" FOREIGN KEY (pipeline_id) REFERENCES ci_pipelines(id) ON DELETE CASCADEci_sources_pipelines 、2つのci_pipelines 行(親と子)を参照します。私たちの通常の戦略は、partition_id をテーブルに追加することでしたが、ここでそれを行うと、すべてのマルチプロジェクトパイプラインを同じパーティションに強制的に所属させることになります。
このテーブルには、partition_id とsource_partition_id の2つのpartition_id 列を追加する必要があります:
Foreign-key constraints:
"fk_be5624bf37" FOREIGN KEY (source_job_id, source_partition_id) REFERENCES ci_builds(id, source_partition_id) ON DELETE CASCADE
"fk_d4e29af7d7" FOREIGN KEY (source_pipeline_id, source_partition_id) REFERENCES ci_pipelines(id, source_partition_id) ON DELETE CASCADE
"fk_e1bad85861" FOREIGN KEY (pipeline_id, partition_id) REFERENCES ci_pipelines(id, partition_id) ON DELETE CASCADEこの解決策は、双方向ドアの決定に最も近いものです:
- 異なるパーティションのパイプラインを参照する能力を保持。
- 同じパーティションにある複数のプロジェクトパイプラインを強制的に参照したい場合は、両方のカラムが同じ値であることを検証する制約を追加できます。
なぜ明示的な論理パーティションIDを使用したいのですか?
論理partition_id を使ってCI/CDデータをパーティショニングすることには、いくつかの利点があります。プライマリキーでパーティショニングすることもできますが、その場合、データがどのように構造化され、パーティションに格納されているかを理解するために、より複雑で認知的な負荷がかかります。
CI/CDデータは階層的なデータです。ステージはパイプラインに属し、ビルドはステージに属し、アーティファクトはビルドに属します(まれな例外を除いて)。私たちは、この階層構造を反映したパーティショニング戦略を設計し、貢献者の複雑さとそれによる認識負荷を軽減しています。パイプラインに関連付けられた明示的なpartition_id 、パイプラインに関連付けられたすべてのリソースを取得しようとするときに、パーティションID番号をカスケードすることができます。12345 partition_id また、PostgreSQLはどのテーブルのどの102パーティションに 102これらのレコードが格納されているかを知ることができます。
また、PostgreSQLはすべてのテーブルで、これらのレコードがどのパーティションに格納されているかを知ることができます。 パイプラインに関連する最新のpartition_id 番号を単一かつ増分的に使用するもう1つの興味深い利点は、理論的には、この番号をRedisやメモリにキャッシュすることで、この番号を見つけるためにデータベースから過剰な読み込みを行うことを避けることができることです。
パイプラインデータのpartition_id 値が単一で統一されているため、プライマリ・キー・ベースのパーティショニングよりも後々選択肢が増えます。
パーティショニングされたテーブルの変更
パーティALTER TABLE ショニング前のテーブルの動作と同様に、パーティショニングされたテーブルに対して文を ALTER TABLE実行することは可能です。ALTER TABLE PostgreSQLが ALTER TABLEパーティショニングされた親テーブルに対して文をALTER TABLE 実行すると ALTER TABLE、全ての子パーティションに対して同じロックを取得し、同期を保つためにそれぞれを更新します。これは、パーティショニングされていないテーブルに対してALTER TABLE :
- PostgreSQLは、パーティショニングされていないテーブルよりも多くのテーブルに対して
ACCESS EXCLUSIVE。各パーティションは親テーブルと同様にロックされ、1つのトランザクションで全てが更新されます。 - ロックの継続時間は、パーティションの数に応じて長くなります。GitLabデータベース上で実行されるすべての
ALTER TABLE文(VALIDATE CONSTRAINT以外)は、テーブルが変更されるごとに小さな一定の時間を要します。PostgreSQLは各パーティションを順番に変更する必要があり、ロックの実行時間が長くなります。パーティション数が多くなるまで、この時間は非常に小さいままです。 -
ALTER TABLEに何千ものパーティションが含まれる場合、max_locks_per_transactionの値が、オペレーション中に必要なすべてのロックをサポートするのに十分な高さであることを確認する必要があります。
大きなパーティションを小さなパーティションに分割
partition_id 100 (計算や見積もりによっては、1000のようにもっと高い場合もあります)。既存のテーブルもすでに大きいので、小さなパーティションに分割したいからです。100から始めると、1、20、45、partition_id のパーティションを作成し、100 からpartition_id を小さい番号に更新することで、既存のレコードをそこに移動させることができます。
PostgreSQLは、すべてのパイプラインリソースに対して同時にトランザクションを実行すれば、一貫した方法でこれらのレコードをそれぞれのパーティションに移動します。大きなパーティションを小さなパーティションに分割することになった場合(その必要があるかどうかはまだ明らかではありません)、バックグラウンドマイグレーションを使用してパーティションIDを更新するだけで、PostgreSQLは十分に賢く、パーティション間で行を移動させることができます。
命名規則
パーティショニングされたテーブルはルーティング・テーブルと呼ばれ、p_ プレフィックスが使用されます。これはクエリ解析のための自動化ツールを構築する際に役立ちます。
ci_builds_101テーブルのパーティションはパーティションと呼ばれ、物理パーティションIDを接尾辞として使用します。既存のCIテーブルは、新しいルーティング・テーブルのゼロ・パーティションになります。テーブルのパーティショニング戦略によっては、1つの物理パーティションに対して多くの論理パーティションを持つことができます。
最初のパーティションのアタッチとロックの取得
最初のテーブルをパーティショニングする際に、PostgreSQL 、そのテーブルと外部キーで参照する他のテーブルすべてにAccessExclusiveLock 。マイグレーションがアプリケーションのビジネスロジックと異なる順序でロックを取得しようとすると、デッドロックが発生する可能性があります。
この問題を解決するために、さらなるデッドロック・エラーを回避する優先順位ロック戦略を導入しました。これにより、ロックの順序を定義し、ロックを取得するかリトライ回数がなくなるまで積極的にリトライし続けることができます。この処理には最大40分かかります。
この戦略により、トラフィックの少ない時間帯(の後、00:00 UTC)に15回リトライした後、ci_builds テーブルのロック獲得に成功しました。
パーティション・ツールでのこの戦略の例を参照してください)。
パーティショニングの手順
データベース・パーティショニング・ツールのドキュメントには、テーブルをパーティショニングするためのステップのリストが記載されています。データセットが増え続ける中、すべてのテーブルがパーティショニングされるまで待つのではなく、パーティショニングのパフォーマンスをすぐに利用したいのです。たとえば、ci_builds_metadata テーブルをパーティショニングした後、新しいパーティションへのデータの書き込みと読み込みを開始したいとします。つまり、partition_id の値をデフォルト値の100 から101 に増やします。これで、パイプライン階層の新しいリソースはすべてpartition_id = 101 で永続化されます。次にパーティショニングするテーブルについては、データベース・ツールの指示に従います:
- FK 参照に
partition_id列を追加します。デフォルト値は100です。 - アプリケーション・ロジックを変更し、
partition_idの値をカスケードするようにします。 -
デプロイ後/バックグラウンドマイグレーションで最近のレコードの
partition_id値を修正します:UPDATE ci_pipeline_metadata SET partition_id = ci_pipelines.partition_id FROM ci_pipelines WHERE ci_pipelines.id = ci_pipeline_metadata.pipeline_id AND ci_pipelines.partition_id in (101, 102); - 外部キー定義の変更
- …
パーティションのメタデータをデータベースに保存
新しいパーティションを作成する効率的なメカニズムを構築し、時間減衰を実装するために、ci_partitions というパーティショニングメタデータテーブルを導入したいと思います。このテーブルには、パーティションごとに多くのパイプラインを持つ、すべての論理パーティションに関するメタデータを格納します。論理パーティションごとに、パイプラインIDの範囲を保存する必要があるかもしれません。partition_id また、どの論理パーティションが “アクティビティ “なのか “アーカイブ “なのかの情報も見つけることができ、データベースの宣言的パーティショニングを使用して、時間依存のパターンを実装するのに役立ちます。
To-Doを行うことで、パーティショニングされたリソースにUnified Resource Identifierを使用することができます。Unified Resource IdentifierにはパイプラインIDへのポインタが含まれ、リソースが格納されているパーティションを効率的に検索することができます。リソースがUIやAPIでURLによって直接参照される場合、これは重要かもしれません。パイプライン123456 やビルド23456 には1e240-5ba0 のような ID を使用できます。ダッシュ- を使用すると、識別子がハイライトされ、マウスのダブルクリックでコピーされるのを防ぐことができます。この問題を避けたい場合は、16進数にはない文字、例えばラテンアルファベットのg からz までの任意の文字、xを使用することができます。その場合、URIの例は1e240x5ba0のようになります。パーティショニングされたリソースのプライマリ識別子(現在では単なる大きな整数です)を更新することを決めた場合、リバランシングが起こったときに識別子が変更されないように、パーティション間のデータのマイグレーションに強いシステムを設計することが重要です。
ci_partitions テーブルには、パーティション識別子、それが有効なパイプラインIDの範囲、パーティションがアーカイブされているかどうかの情報が格納されます。タイムスタンプを持つ追加カラムも役立ちます。
パーティショニングを使った時間減衰パターンの実装
ci_partitions 、宣言的なパーティショニングを使用して時間経過パターンを実装することができます。どの論理パーティションをアーカイブするかをPostgreSQLに指示することで、以下のようなSQL問い合わせを使用して、これらのパーティションからの読み取りを停止することができます。
SELECT * FROM ci_builds WHERE partition_id IN (
SELECT id FROM ci_partitions WHERE active = true
);
このクエリによって、読み込むパーティションの数を制限することができ、CI/CDデータのデータ保持ポリシーを使用して、”アーカイブされた “パイプラインデータへのアクセスを削減することができます。理想的には、一度に2つ以上のパーティションから読み込みたくないので、自動パーティショニングのメカニズムを時間減衰ポリシーに合わせる必要があります。アーカイブされたデータに対する新しいアクセスパターンを、おそらくAPIを通して実装する必要がありますが、PostgreSQLにアーカイブされたデータを格納するコストはこの方法で大幅に削減されます。
この説明の範囲外の技術的な詳細がいくつかありますが、この戦略を使用することで、データを “アーカイブ “し、PostgreSQLクラスタに保存するコストを、ブール値の列の値を切り替えることで大幅に削減することができます。
パーティショニングされたデータへのアクセス
アーカイブされているかどうかに関わらず、GitLab のほとんどの場所でパーティション化されたデータにアクセスできるようになります。マージリクエストページでは、マージリクエストが何年も前に作成されたものであっても、常にパイプラインの詳細を表示します。ci_partitions がパイプライン ID とpartition_id を関連付けたルックアップテーブルになり、パイプラインデータが格納されているパーティションを見つけることができるようになるからです。
パイプライン、ビルド、アーティファクトなどを検索するには、アクセスを制限する必要があります。そのため、アーカイブされたパイプラインデータを検索する優れた方法を見つける必要があります。UIとAPIで、アーカイブされたデータにアクセスするための異なるアクセスパターンを持つ必要があります。
PostgreSQLでpartition_id パーティショニングキーの使用を強制するには、いくつかの課題があります。これをサポートするアプリケーションの更新を容易にするために、私たちは概念実証のマージリクエストで新しいクエリ分析器を設計しました。これはパーティショニングキーを使用していないクエリを見つけるのに役立ちます。
別の概念実証マージリクエストと 関連イシューでは、ユニフォームpartition_id を使用することで、SQLクエリでパーティショニングキーを提供できるように、追加のスコープ修飾子でRailsアソシエーションを拡張できることを示しました。
インスタンス依存のアソシエーションを使えば、たとえば関連するパイプラインリソースを取得するSQLクエリにパーティショニングキーを簡単に追加できます:
has_many :builds, -> (pipeline) { where(partition_id: pipeline.partition_id) }
このアプローチの問題点は、インスタンス依存の関連付けをプリロードで使用できないため、プリロードが非常に難しくなることです:
ArgumentError: The association scope 'builds' is instance dependent (the
scope block takes an argument). Preloading instance dependent scopes is not
supported.
クエリ・アナライザ
パーティショニングされたテーブルですべてが機能し続けるように、修正が必要なクエリを検出するために2つのクエリ・アナライザを実装しました:
- 1つはルーティングテーブルを経由しないクエリを検出するアナライザです。
-
WHERE節でpartition_idを指定せずにルーティング・テーブルを使用するクエリを検出するアナライザ。
まず、test 環境で最初のアナライザを有効にして、既存の壊れたクエリを検出しました。また、production 環境でも有効にしていますが、スケーラビリティの懸念から、トラフィックの小さなサブセット(0.1% )に対して有効にしています。
2番目のアナライザは将来の反復で有効にする予定です。
主キー
プライマリ・キーには、テーブルを分割するためのパーティショニング・キー・カラムを含める必要があります。
(id, partition_id)次に、主キー制約を削除し、作成した新しいインデックスを使用して、新しい主キー制約を設定します。
ActiveRecord は複合主キーをサポートしていないので、id 列を主キーとして扱うように強制しなければなりません:
class Model < ApplicationRecord
self.primary_key = 'id'
end
アプリケーションレイヤーはデータベース構造を知らないので、ActiveRecord からの既存のクエリはすべて、id データへのアクセスにカラムを id使用し続けます。id このアプローチにはいくつかのリスクがあります。なぜなら id、partition_id 、id 同じ値を持つモデルが重複してしまうようなアプリケーションコードを作成 idする可能性があるからです。partition_id このリスクを軽減するためには、すべての挿入がデータベースのシーケンスを使用して、id に値を入力することを保証しなければなりません。挿入時に手動でidを割り当てることは避けなければなりません。
外部キー
外部キーは、主キーであるか一意制約を形成するカラムを参照しなければなりません。これらのストラテジーを使って定義することができます:
パーティションIDを共有するルーティング・テーブル間
同じパイプライン階層に属するリレーションでは、partition_id カラムを共有して外部キー制約を定義することができます:
p_ci_pipelines:
- id
- partition_id
p_ci_builds:
- id
- partition_id
- pipeline_id
この場合、p_ci_builds.partition_id は、ビルドとパイプラインのパーティションを示します。この場合、 は、ビルドとパイプラインのパーティションを示します:
ALTER TABLE ONLY p_ci_builds
ADD CONSTRAINT fk_on_pipeline_and_partition
FOREIGN KEY (pipeline_id, partition_id)
REFERENCES p_ci_pipelines(id, partition_id) ON DELETE CASCADE;
異なるパーティションIDを持つルーティングテーブル間
CIドメイン内のすべてのリレーションでpartition_id を再利用することはできません。この場合、別の属性として値を格納する必要があります。例えば、冗長なパイプラインをキャンセルする場合、古いパイプラインの行に、それをキャンセルした新しいパイプラインのIDをauto_canceled_by_id として格納します:
p_ci_pipelines:
- id
- partition_id
- auto_canceled_by_id
- auto_canceled_by_partition_id
この場合、キャンセルされたパイプラインがキャンセルされたパイプラインと同じ階層に属していることを保証できないため、そのパーティション、auto_canceled_by_partition_id 、FKを格納する追加の属性が必要になります:
ALTER TABLE ONLY p_ci_pipelines
ADD CONSTRAINT fk_cancel_redundant_pipelines
FOREIGN KEY (auto_canceled_by_id, auto_canceled_by_partition_id)
REFERENCES p_ci_pipelines(id, partition_id) ON DELETE SET NULL;
ルーティングテーブルと通常のテーブルの間
CIドメイン内のすべてのテーブルがパーティショニングされているわけではないので、パーティショニングされていないテーブルを参照するルーティングテーブルを用意します。例えば、ci_pipelines からexternal_pull_requests を参照します:
FOREIGN KEY (external_pull_request_id)
REFERENCES external_pull_requests(id)
ON DELETE SET NULL
この場合、FK定義をパーティションレベルからルーティングテーブルに移動するだけで、新しいパイプラインパーティションがそれを使用できるようになります:
ALTER TABLE p_ci_pipelines
ADD CONSTRAINT fk_external_request
FOREIGN KEY (external_pull_request_id)
REFERENCES external_pull_requests(id) ON DELETE SET NULL;
通常のテーブルとルーティング・テーブルの間
CIドメインのテーブルのほとんどは、ルーティングテーブルになるテーブルを少なくとも1つ参照しています。例えば、ci_pipeline_messages はci_pipelines を参照しています。これらの定義はルーティングテーブルを使用するように更新する必要があり、そのためにpartition_id :
p_ci_pipelines:
- id
- partition_id
ci_pipeline_messages:
- id
- pipeline_id
- pipeline_partition_id
外部キーは
ALTER TABLE ci_pipeline_messages ADD CONSTRAINT fk_pipeline_partitioned
FOREIGN KEY (pipeline_id, pipeline_partition_id)
REFERENCES p_ci_pipelines(id, partition_id) ON DELETE CASCADE;
古いFK定義は削除する必要があります。そうしないと、ci_pipeline_messages 、非ゼロ・パーティションのパイプラインIDを持つ新規挿入は参照エラーで失敗します。
インデックス
To-Doは、PostgreSQL 、テーブルのすべてのパーティションに単一のインデックス(一意であるかどうかにかかわらず)を作成することはできないことを学びました。
この問題を解決する1つの方法は、一意性制約の中にパーティショニングキーを埋め込むことです。
これは、トークンの前に16進数でパーティションIDを付加し、連結した文字列をデータベースに格納することを意味します。そのためには、トークンの先頭に適切なバイト数を確保し、将来の最大パーティション数に対応する必要があります。base-16で16ビットに相当する4文字を確保すれば十分でしょう。この方法でエンコードできる最大数はFFFFで、10進数では65535になります。
これは、グローバルな一意性を保つのに十分な、パーティションごとの一意制約を提供するでしょう。
また、p_ci_pipelines のように、すべてのクエリがパーティショニングされたスキーマやパーティショニングされたルーティング・テーブルを対象としていることを確認するために、ゼロ・パーティションや、ルーティング・テーブルの最初のパーティションとしてアタッチされたレガシー・テーブルの直接的な使用を検出できるクエリ・アナライザを設計しました。
プロジェクトIDまたはネームスペースIDを使用してパーティショニングしてはどうでしょうか?
project_id 、namespace_id 。シャーディングやポッドは、アプリケーションの別のレイヤーで解決すべき別の問題だからです。なぜなら、シャーディングとポッド化は、アプリケーションの別のレイヤーで、解決すべき別の問題だからです。これは、読み取り頻度の低いデータが蓄積されるにつれてパフォーマンスが時間とともに悪化するという元の問題文を解決するものではありません。将来的にはポッドを導入し、データが関連付けられているグループやプロジェクトに基づいてデータを分離する主要なメカニズムになるかもしれません。
理論的には、project_id 、namespace_id のいずれかを2つ目のパーティショニング次元として使用することもできますが、すでに非常に複雑な問題にさらに複雑さを加えることになります。
パーティショニングはキューイング・テーブルを構築します
また、ビルド・キューイング・テーブルのパーティショニングも行いたいと考えています。現在、ci_pending_builds とci_running_builds の2つがあります。これらのテーブルは他のCI/CDデータテーブルとは異なり、私たちの製品では24時間後に保存されているすべてのデータを無効にするビジネスルールがあるからです。
その結果、これらのデータベーステーブルをパーティショニングするために、24時間以上経過したらパーティションを完全に削除し、常にルーティングテーブルを介して2つのパーティションから読み出すという、異なる戦略を使用する必要があります。これらのテーブルをパーティショニングする戦略はよく理解されていますが、パーティションの作成と削除を管理するRubyベースの自動化が必要です。これを実現するために、私たちはデータベースチームと協力して、CI/CDデータパーティショニングをサポートするために既存のデータベースパーティショニングツールを適応させる予定です。
リスクを減らすための反復
この戦略により、CI/CDパーティショニングを実装するリスクを許容できるレベルまで低減できるはずです。また、本番環境で問題が発生した場合にゼロパーティションを切り離せるようにするため、最初は2つのパーティションからのみ読み出すパーティショニングを実装することに重点を置いています。後述するすべての反復フェーズにはリバート戦略があり、データベースの変更を出荷する前に、ベンチマーク環境でテストしたいと考えています。
この作業におけるリスクを減らす主な方法は、反復と可逆性を持たせることです。この文書で説明されている変更を、安全で信頼できる方法で出荷することが、私たちの優先事項です。
実装を進めるにつれて、設計を反復し、インクリメンタルなロールアウトをサポートし、何か問題が発生した場合に変更を元に戻すことをよりよくコントロールする方法をさらに見つける必要があります。データベーススキーマの変更を反復的に出荷することは時に困難であり、本番環境へのインクリメンタルなロールアウトをサポートすることはさらに困難です。しかし、これは可能です。ただ、さらなる創造性が必要になることがあります。このような例もあります:
パーティショニングされたスキーマのインクリメンタルなロールアウト
最初のパーティショニングされたルーティングテーブル(おそらくp_ci_pipelines )を導入し、そのゼロパーティション(ci_pipelines )をアタッチしたら、具体的なパーティションゼロではなく、新しいルーティングテーブルとのやり取りを開始する必要があります。通常、Ci::Pipeline Railsモデルが使用するデータベーステーブルを、self.table_name = 'p_ci_pipelines' のようにオーバーライドします。残念ながら、この方法はインクリメンタルなロールアウトをサポートしないかもしれません。self.table_name はアプリケーションの起動時に読み込まれ、後でアプリケーションを再起動せずにこの変更を元に戻すことができないかもしれないからです。
これを解決するひとつの方法として、Ci::Pipeline を継承するCi::Partitioned::Pipeline モデルを導入することが考えられます。このモデルでは、self.table_name をp_ci_pipeline に設定し、Ci::Pipeline.partitioned からそのメタクラスをスコープとして返します。これにより、機能フラグを使用して、ci_pipelines からの読み込みをp_ci_pipelines にルーティングし、単純な revert 戦略を使用できるようになります。
パーティショニングされたリードのインクリメンタルな実験
もう1つの例は、別のパーティションをアタッチすることを決定するタイミングに関するものです。フェーズ1の目標は、パーティショニングされたスキーマ/ルーティングテーブルごとに2つのパーティションを持つことです。つまり、p_ci_pipelines 、パーティションゼロとしてci_pipelines 、新しいデータ用にci_pipelines_p1 パーティションを作成します。p_ci_pipelines p1 また、パーティショニングのパフォーマンスとオーバーヘッドを評価するために、複数のパーティションをターゲットにした読み取りを繰り返し実験する必要があります。
そのためには、古い_データをci_pipelines_m1 (マイナス1)パーティションに繰り返し移動します。おそらく、partition_id = 1 を作成し、本当に古いパイプラインをそこに移動させるでしょう。その後、m1 パーティションに繰り返しデータをマイグレーションし、_新しい(まだ作成されていない)データ用に新しいパーティションp1 を作成する前に、影響やパフォーマンスを測定し、信頼性を高めることができます。
イテレーション
まずフェーズ1のイテレーションに焦点を当てたいと思います。この反復の目標であり主な目的は、最大6つのCI/CDデータベーステーブルを6つのルーティングテーブル(パーティショニングスキーマ)と12のパーティションに分割することです。これにより、RailsのSQLクエリはほとんど変更されませんが、データベースのパフォーマンスが低下した場合に「ゼロパーティション」の緊急切り離しを実行できるようになります。これによってユーザーは古いデータから切り離されますが、アプリケーションは稼働し続けるので、アプリケーション全体の停止よりはましです。
- フェーズ0:CI/CDデータ・パーティショニング戦略の構築:To-Do.✅
-
フェーズ1: CI/CDデータベースの6つの大きなテーブルをパーティショニングします。
- 6つのデータベーステーブルすべてにパーティション化されたスキーマを作成します。
- すべてのパーティショニングされたリソースに
partition_id、カスケードする方法を設計します。 - ルーティング・テーブルをターゲットにしていることを検証する初期クエリ・アナライザを実装します。
- パーティショニングされたデータベース・テーブルにゼロ・パーティションをアタッチします。
- ルーティング・テーブルとパーティショニング・テーブルをターゲットにアプリケーションを更新します。
- このソリューションのパフォーマンスと効率を測定します。
戦略を戻します:ルーティングテーブルの代わりに具体的なパーティションを使うように戻します。
-
フェーズ2: パーティショニング・キーを追加して、パーティショニング・テーブルを対象とするSQLクエリを追加します。
- パーティショニング・テーブルを対象とするクエリが適切なパーティショニング・キーを使用しているかどうかをチェックするクエリ・アナライザを実装します。
- 既存のクエリを修正し、すべてのクエリがフィルタとしてパーティショニング・キーを使用していることを確認します。
戦略を戻します:クエリごとに機能フラグを使用します。
-
フェーズ3:新しいパーティショニングされたデータアクセスパターンを構築します。
- 新しいAPIを構築するか、既存のAPIを拡張して、時間減衰データ保持ポリシーに基づいて除外されるはずのパーティションに格納されたデータへのアクセスを許可します。
リバート戦略:機能フラグ。
-
フェーズ4:パーティショニングの上に構築された時間減衰メカニズムの導入。
- 時間逓減ポリシーメカニズムの構築。
- GitLab.comでタイムディケイ戦略を有効にします。
-
フェーズ5:パーティションを自動的に作成する仕組みを導入します。
- 自動でパーティションを作成できるようにします。
- 新しいアーキテクチャをセルフマネージド・インスタンスに提供します。
下図は、この計画をガントチャートで可視化したものです。下のチャート上の日付は、計画をよりよく視覚化するための単なる見積もりであり、これらは期限ではなく、いつでも変更可能です。
結論
私たちはCI/CDデータをパーティショニングするための強固な戦略を構築したいと考えています。というのも、マルチテラバイトのPostgreSQLインスタンスのデータベーススキーマの管理でミスを犯した場合、ダウンタイムの可能性なしに簡単に元に戻せない可能性があるからです。これが、パーティショニング戦略の研究と改良に多大な時間を費やしている理由です。この文書で説明する戦略もまた、反復される可能性があります。リスクを減らし、計画を改善するためのより良い方法が見つかったら、このドキュメントも更新する必要があります。
私たちは大規模なデータマイグレーションを回避する方法を何とか見つけ、CI/CDデータを分割するための反復的な戦略を構築しています。知識を共有し、他のチームメンバーからのフィードバックを求めるために、私たちの戦略をここに文書化しました。
誰
DRI
| ロール | 誰 |
|---|---|
| Author | グジェゴシュ・ビゾン、プリンシパル・エンジニア |
| レコメンダー | カミル・トルチンスキ, シニア・ディスティングイッシュト・エンジニア |
| 製品リーダーシップ | ジャッキー・ポーター、プロダクト・マネジメント・ディレクター |
| エンジニアリング・リーダーシップ | キャロライン・シンプソン、エンジニアリング・マネージャー / シェリル・リー、シニア・エンジニアリング・マネージャー |
| リード・エンジニア | マリウス・ボビン、シニア・バックエンドエンジニア |
| シニアエンジニア | シニアバックエンドエンジニア Maxime Orefice |
| シニアエンジニア | Tianwen Chen, シニアバックエンドエンジニア |