GitLabのスケーラビリティ
このセクションでは、スケーラビリティと信頼性に関連するGitLabの現在のアーキテクチャについて説明します。
リファレンスアーキテクチャの概要
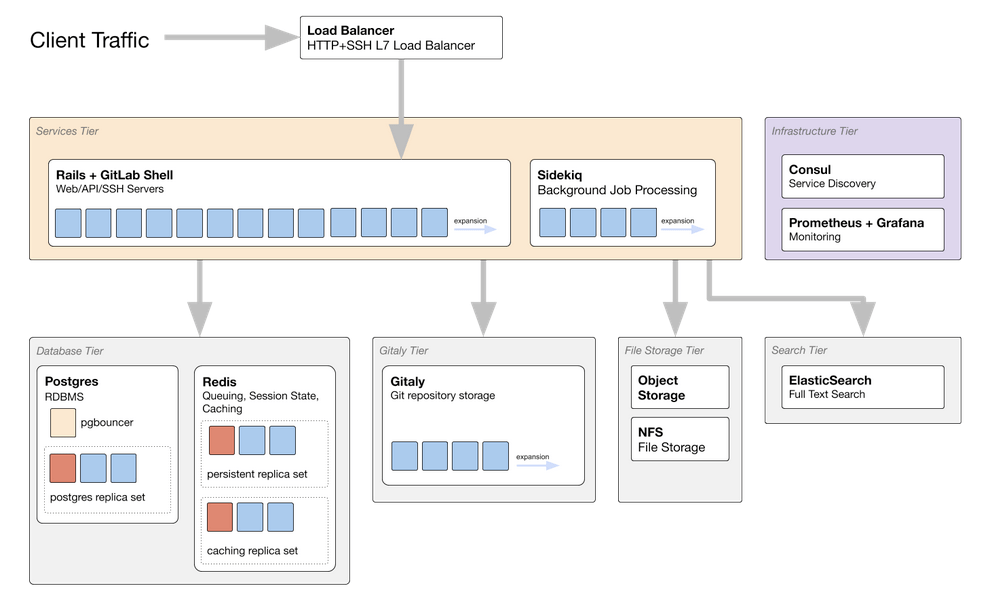
上の図は、GitLabのリファレンスアーキテクチャを5万ユーザーにスケールアップしたものです。各コンポーネントについては後述します。
コンポーネント
PostgreSQL
PostgreSQLデータベースはプロジェクト、イシュー、マージリクエスト、ユーザーなどのすべてのメタデータを保持します。スキーマはRailsアプリケーションのdb/structure.sqlで管理されます。
GitLab Web/APIサーバーとSidekiqノードは、Railsオブジェクトリレーショナルモデル(ORM) を使ってデータベースと直接やり取りします。ほとんどのSQLクエリはこのORMを使ってアクセスされますが、パフォーマンスや高度なPostgreSQL機能(再帰的CTEやLATERAL JOINなど)を利用するためにカスタムSQLを書くこともあります。
アプリケーションはデータベーススキーマと緊密に結合しています。アプリケーションが起動すると、Railsはデータベーススキーマをクエリし、要求されたデータのテーブルとカラムタイプをキャッシュします。このスキーマキャッシュがあるため、アプリケーションの実行中にカラムやテーブルを削除すると、ユーザーに500エラーが表示されることがあります。このため、カラムの削除やその他のダウンタイムなしの変更を行うプロセスが用意されています。
マルチテナンシー
単一のデータベースを使用して、すべての顧客データを保存します。各ユーザーは多くのグループやプロジェクトに所属することができ、グループやプロジェクトへのアクセスレベル(ゲスト、開発者、メンテナーを含む)によって、ユーザーが見ることができるものやアクセスできるものが決まります。
管理者権限を持つユーザーは、すべてのプロジェクトにアクセスでき、ユーザーになりすますこともできます。
シャーディングとパーティショニング
データベースは分割されていません。現在、すべてのデータは1つのデータベースで多くの異なるテーブルに格納されています。これは単純なアプリケーションには有効ですが、データセットが大きくなるにつれて、多くの行を持つテーブルを持つ1つのデータベースをメンテナーし、サポートすることが難しくなります。
これに対処する方法は2つあります:
- パーティショニング。テーブルのデータをローカルに分割します。
- シャーディング。複数のデータベースにデータを分散。
パーティショニングはPostgreSQLの組み込み機能であり、アプリケーションの変更は最小限で済みます。しかし、PostgreSQL 11が必要です。
例えば、自然なパーティショニング方法は、日付でテーブルをパーティショニングすることです。例えば、events テーブルとaudit_events テーブルはこの種のパーティショニングの自然な候補です。
シャーディングはより難しく、スキーマとアプリケーションに大きな変更を加える必要があります。たとえば、多くの異なるデータベースにプロジェクトを格納する必要がある場合、”異なるプロジェクトにまたがるデータをどのように取り出すか “という問題にすぐにぶつかります。これに対する一つの答えは、データアクセスをアプリケーションからデータベースを抽象化したAPI呼び出しに抽象化することですが、これはかなりの作業量になります。
シャーディングをアプリケーションからある程度抽象化するのに役立つソリューションもあります。たとえば、Citus Dataをよく見てみたいと思います。Citus Dataは、ActiveRecordモデルにテナントIDを追加するRailsプラグインを提供しています。
機能バーティカルに基づいてシャーディングを行うこともできます。これはマイクロサービスによるシャーディングのアプローチで、各サービスは境界のあるコンテキストを表し、サービス固有のデータベースクラスタでオペレーションします。このモデルでは、データは内部キー(テナントIDなど)ではなく、チームや製品の所有権に基づいてディストリビューションされます。しかし、これは従来のデータ指向のシャーディングと多くの課題を共有しています。例えば、データの結合はクエリレイヤーではなくアプリケーション自体で行わなければなりません(GraphQLのようなレイヤーを追加することで軽減されるかもしれませんが)。また、効率的に実行するためには真の並列処理(つまり、データレコードを収集し、それを圧縮するための散在収集モデル)が必要ですが、これはRubyベースのシステムではそれ自体が課題です。
データベースのサイズ
最近のデータベースチェックで、GitLab.comのテーブルサイズの内訳がわかりました。merge_request_diff_files には1TB以上のデータが含まれているので、まずこのテーブルを削減/削除したいと思います。GitLabはオブジェクトストレージにdiffを保存するためのサポートを持っています。
高い可用性
高可用性と冗長性を提供するには、いくつかの戦略があります:
- ライトアヘッド・ログ(WAL) オブジェクトストレージ(例えばS3やGoogle Cloud Storage)にストリーム。
- リードレプリカ(ホットバックアップ)。
- 遅延レプリカ
ある時点からデータベースをリストアするには、そのインシデントの前にベース バックアップが取得されている必要があります。デー タ ベース がそのバ ッ ク ア ッ プか ら 復元 さ れ る と 、 デー タ ベース は タ ーゲ ッ ト 時刻に達するま で順番に WAL ログを適用で き ます。
GitLab.comでは、ConsulとPatroniが連携してリードレプリカとのフェイルオーバーを調整します。OmnibusにはPatroniが同梱されています。
ロードバランシング
GitLab EEはリードレプリカを使ったロードバランシングをアプリケーションでサポートしています。このロードバランサは、従来の標準的なロードバランサにはないアクションを行います。例えば、アプリケーションはレプリケーションの遅延が少ない場合のみレプリカを考慮します(例えば、WALデータの遅延が100MB以下)。
PgBouncer
PostgreSQLはリクエストごとにバックエンドプロセスをフォークするので、PostgreSQLがサポートできる接続数には限りがあります。PgBouncerのようなコネクションプーラーを使わないと、接続の制限にぶつかる可能性があります。制限に達すると、GitLabは接続が利用できるようになるのを待つためにエラーを発生させたり速度を落としたりします。
高い可用性
PgBouncerはシングルスレッドです。トラフィックが多い場合、PgBouncerはシングルコアを飽和する可能性があり、バックグラウンドジョブやWebリクエストの応答時間が遅くなる可能性があります。この制限にアドレスする方法は2つあります:
- 複数のPgBouncerインスタンスを実行します。
- マルチスレッド接続プーラを使用します。
いくつかのLinuxシステムでは、同じポート上で複数のPgBouncerインスタンスを実行することが可能です。
GitLab.comでは、複数のPgBouncerインスタンスを異なるポートで実行し、1つのコアが飽和しないようにしています。
さらに、プライマリとセカンダリと通信するPgBouncerインスタンスは少し異なる設定になっています:
- 異なるアベイラビリティゾーンにある複数のPgBouncerインスタンスがPostgreSQLプライマリと通信します。
- 複数のPgBouncerプロセスはPostgreSQLのリードレプリカとコロケーションしています。
レプリカの場合、コロケーションはネットワークホップを減らし、待ち時間を減らすので有利です。しかし、プライマリにとっては、PgBouncerが単一障害点となりエラーを引き起こすため、コロケーションは不利です。フェイルオーバーが発生すると、2つのことが起こります:
- プライマリがネットワークから消える
- プライマリがレプリカになります。
最初のケースでは、PgBouncerがプライマリにコロケーションされている場合、データベース接続がタイムアウトしたり、接続に失敗したりして、ダウンタイムが発生します。ロードバランサーの前に複数のPgBouncerインスタンスを置くことで、プライマリに接続することができます。
2つ目のケースでは、新しく切り離されたレプリカへの既存の接続が書き込みクエリを実行し、失敗する可能性があります。フェイルオーバーの間、プライマリと通信しているPgBouncerをシャットダウンし、それ以上トラフィックが到着しないようにすることが有効です。別の方法として、アプリケーションにフェイルオーバーイベントを認識させ、接続を終了させることもできます。
Redis
GitLabでRedisを使う方法は3つあります:
- キュー:SidekiqジョブはジョブをJSONペイロードにマーシャルします。
- 永続的な状態:セッションデータと排他的リース。
- キャッシュ:リポジトリデータ(ブランチやタグ名など)とビューパーシャル。
GitLabインスタンスが大規模に稼働している場合、Redisの利用を別々のRedisクラスターに分割することは2つの理由で役立ちます:
- それぞれ異なる永続性要件があります。
- 負荷分離。
例えば、maxmemory 設定オプションを設定することで、キャッシュ・インスタンスを(LRU) キャッシュのように動作させることができます。このオプションはキューや永続クラスタには設定すべきではありません。これはジョブを床に落とすことになり、多くの問題(マージが実行されない、ビルドが更新されないなど)を引き起こします。
また、Sidekiqはかなり頻繁にキューをポーリングしており、このアクティビティは他のクエリを遅くする可能性があります。このため、Sidekiq専用のRedisクラスターを持つことで、パフォーマンスを向上させ、Redisプロセスの負荷を軽減することができます。
高可用性/リスク
シングルコア:PgBouncerと同様に、1つのRedisプロセスは1つのCoreしか使用できません。マルチスレッドには対応していません。
間抜けなセカンダリRedisのセカンダリ(レプリカとも呼ばれます)は実際には負荷を処理しません。PostgreSQLのセカンダリとは異なり、読み込みクエリすら処理しません。セカンダリはプライマリからデータを複製し、プライマリに障害が発生した場合にのみデータを引き継ぎます。
Redisのセンチネル
Redis Sentinelはプライマリを監視することで、Redisの高可用性を提供します。複数のSentinelsがプライマリがいなくなったことを検出すると、Sentinelsは選挙を実行して新しいリーダーを決定します。
障害モード
リーダーなし:Redisクラスターはプライマリが存在しないモードになることがあります。たとえば、Redisノードが間違ったノードに従うように誤って設定されている場合に起こります。この場合、REPLICAOF NO ONE コマンドを使用して、1つのノードを強制的にプライマリノードにする必要があることがあります。
Sidekiq
SidekiqはRuby on Railsアプリケーションで使われるマルチスレッドのバックグラウンドジョブ処理システムです。GitLabでは、Sidekiqは以下のような多くのアクティビティで重い仕事をこなします:
- プッシュ後のマージリクエストの更新。
- Eメールメッセージの送信
- ユーザー作成者の更新。
- CI ビルドとパイプラインの処理
ジョブの完全なリストは GitLab コードベースのapp/workers とee/app/workers ディレクトリにあります。
暴走キュー
Sidekiqのキューにジョブが追加されると、Sidekiqのワーカースレッドはこれらのジョブをキューから引き出し、追加されたジョブよりも速いペースで完了させる必要があります。アンバランスが発生すると(例えば、データベースの遅延や遅いジョブ)、Sidekiqのキューは膨れ上がり、キューの暴走につながる可能性があります。
ここ数カ月では、PostgreSQL、PgBouncer、Redisの遅延により、これらのキューの多くが膨れ上がっています。例えば、PgBouncerが飽和すると、ジョブはデータベース接続を取得するまでに数秒待つことになり、これが連鎖的に大きな速度低下を引き起こす可能性があります。これらの基本的な相互接続を最適化することが先決です。
しかし、キューがタイムリーに排出されるようにするための戦略はいくつかあります:
- 処理能力を追加します。これは、SidekiqまたはSidekiq Clusterのインスタンスを増やすことで可能です。
- ジョブをより小さな作業単位に分割します。たとえば、
PostReceiveはプッシュの各コミットメッセージを処理していましたが、現在はこれをProcessCommitWorkerにファームアウトしています。 - Sidekiqの処理をキュータイプ別に再分配/再分散します。長時間実行されるジョブ(例えば、プロジェクトのインポートに関連するジョブ)は、高速に実行されるジョブ(例えば、メールの配信)を圧迫することがよくあります。私たちはこのテクニックを使用して、既存のSidekiqデプロイを最適化しました。
- ジョブを最適化します。不要な作業を排除し、ネットワークコール(SQLやGitalyを含む)を削減し、プロセッサ時間を最適化することで、大きなメリットを得ることができます。
Sidekiqログから、どのジョブが最も頻繁に実行され、または最も時間がかかるかを確認できます。例えば、これらのKibanaビジュアライゼーションは、最も総時間を消費するジョブを示しています:
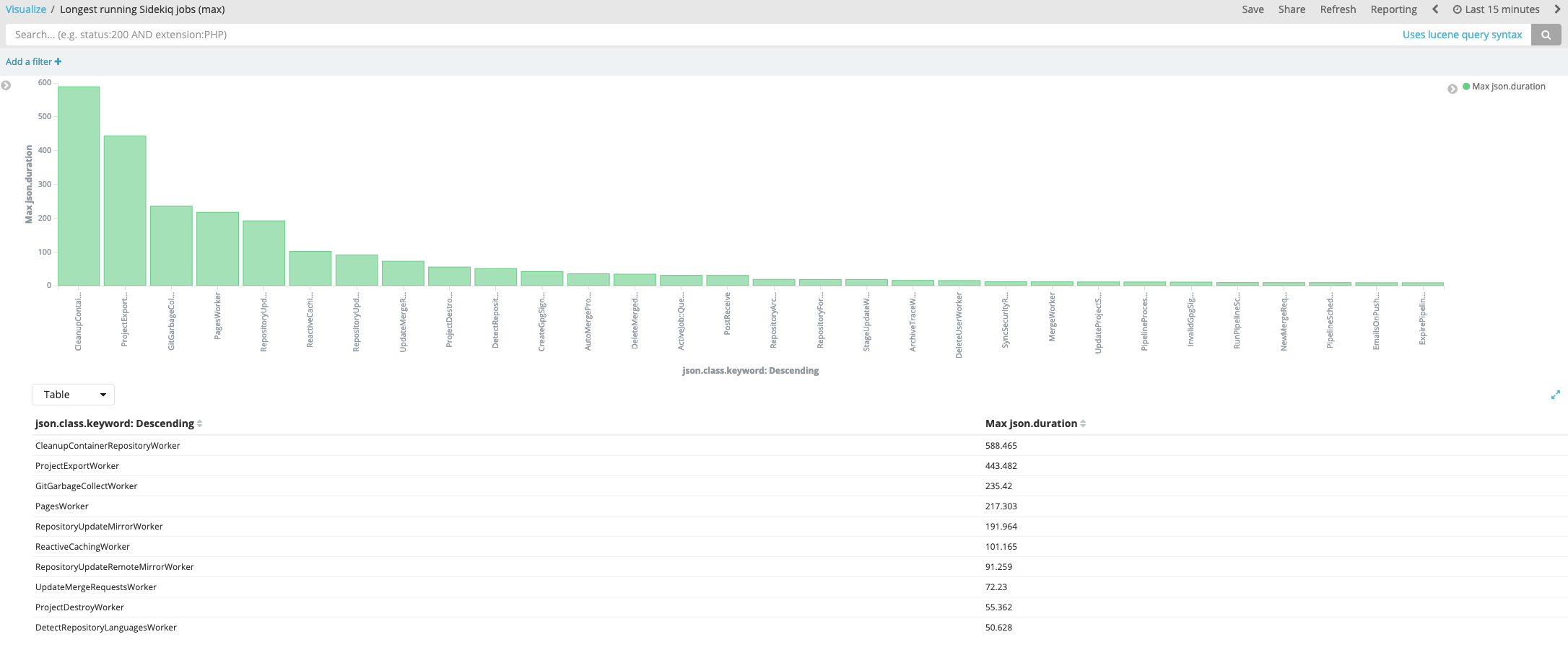
これは、所要時間が最も長いジョブを示しています: