
エラー予算詳細ダッシュボード
エラー予算詳細ダッシュボードを使用すると、特定の時点で費やされたエラー予算を調べることができます。デフォルトでは、ダッシュボードは過去28日間を表示します。時間範囲コントロールまたはグラフの1つで範囲を選択して調整できます。
このダッシュボードは、サービスレベル・モニタリングに使用するダッシュボードと同じ種類のものです。例えば、ウェブサービス(GitLab内部)の概要ダッシュボードをご覧ください。
エラー予算パネル
各ダッシュボードの上部には、エラーバジェットのパネルがあります。ここでは、時間ベースの目標が範囲に応じて調整されます。例えば、28日あたり20分だった予算が、7日間ではその1/4になっています:

また、Grafanaは数値を丸めることに留意してください。この例では、費やされた時間の合計は5分24秒なので、予算を24秒オーバーしています。
また、アトリビューションパネルには、選択した範囲内で発生した失敗のみが表示されます。
これら2つのパネルは、「公式」エラーバジェットのビューを表し、SLIが無視された場合を考慮しています。アトリビューション・パネルは、選択した期間に最も貢献したコンポーネントを表示します。
以下のパネルは、GitLab.comの可用性に貢献するすべてのSLIを考慮しています。これには、公式エラー予算では無視されるSLIも含まれます。
集計のための時系列
集計用の時系列パネルには、すべて3つのコンテナが含まれています:
- Apdex:1つまたは複数のSLIのApdexスコア。スコアが高いほど良好。
- エラー比率:1つまたは複数のSLIのエラー比率。低いほどよい。
- Requests Per Second:1秒あたりのオペレーション数。高いほどエラーバジェットへの影響が大きくなります。
Apdexとエラー率パネルには、2つの警告しきい値もあります:
-
1時間のしきい値:高速燃焼率。
このラインを超えると、この1時間で月間予算の2%を使ったことになります。
-
6時間のしきい値:スローバーンレート。
このラインを超えると、この6時間で予算の2%を使ったことになります。
あるSLIのエラー率やApdexがない場合、パネルは非表示になります。
これらの警告ウィンドウの詳細については、Google SRE ワークブックを参照してください。
ステージグループに対するこれらのメトリクスに関するアラートはありません。この作業はエピック 615 で議論されています。もしこれがあなたのグループに必要なものであれば、そこでお知らせください。
ステージグループの集計
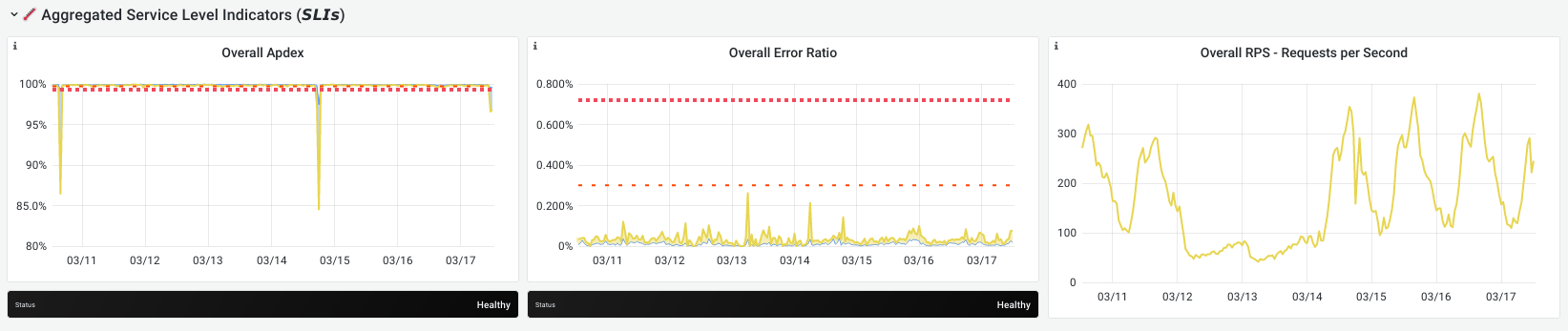
ステージグループ集計は、時間経過に伴うエラー予算のApdexとエラー部分のグラフを表示します。Apdexグラフの凹みが小さいほど、またはエラー率グラフのピークが大きいほど、その時点でより多くの予算が費やされていることを示します。
三番目のグラフは、すべての SLI のすべてのリクエスト率の合計です。高いほど、より多くのトラフィックがあったことを意味します。
多くの予算が費やされた特定の瞬間を拡大するには、グラフで適切な時間を選択します。
サービスレベル指標

この時系列は、ステージグループのエラー予算に貢献する可能性のある各SLIの内訳を示します。ステージグループの集計と同様に、Apdexスコア、エラー率、リクエスト率がコンテナで表示されます。
ここでは、説明パネルも表示し、SLIを説明し、他の監視ツールにリンクします。Kibana のログ (📖) または可視化 (📘) へのリンクは、ステージグループの機能カテゴリにスコープされ、選択した範囲に制限されます。Kibana のログは 7 日間しか保存されないことに留意してください。
グラフでは、サービスごとに 1 行が表示されます。前の例の画像では、rails_requests はweb、api 、git サービスの SLI です。
Sidekiqはこのダッシュボードには含まれていません。エピック700で追跡しています。