
ステージグループの観測可能性
オブザーバビリティとは、システム内に可視性を導入し、各コンポーネントの状態をコンテキストとともに確認・理解することで、パフォーマンス・チューニングやデバッグをサポートすることです。SaaSプラットフォームを大規模に運用するためには、豊富で詳細なオブザーバビリティ・プラットフォームが必要です。
ステージ・グループが情報を利用できるようにするため、私たちは機能カテゴリごとにメトリクスを集約し、この情報をグループに合わせたダッシュボードに表示しています。グループによって構築された機能のメトリクスのみが、グループのダッシュボードに表示されます。
フィルタリングされたビューにより、グループは、集計されたデータを表示する際に見逃す可能性のあるバグやパフォーマンスの低下を発見することができます。
ダッシュボードの詳細については、以下を参照してください:
- ダッシュボード:ダッシュボードの場所と使用方法に関する一般的な概要。
- ステージグループダッシュボード:ステージグループダッシュボードの使用方法とカスタマイズ方法。
- エラー予算の詳細:エラー予算を時系列で調べる方法。
エラー予算
エラーバジェットは、GitLab.comの監視に使っているのと同じサービスレベル指標(SLI)から計算されます。ステージグループの28日間の可用性は、グループの機能にスコープされていることを除けば、GitLab.comのために計算する毎月の可用性と同等です。
エラーバジェットの使い方について詳しくは、エンジニアリングエラーバジェットのハンドブックページをご覧ください。
デフォルトでは、両方のダッシュボードのパネルの最初の行に、ステージグループのエラーバジェットが表示されます。この行は、グループが所有するフィーチャーが全体の可用性にどのように貢献しているかを示しています。
公式バジェットは28日間にわたって集計されます。ステージグループのダッシュボードで確認できます。エラー予算詳細ダッシュボードでは、範囲をカスタマイズできます。
情報は2つの形式で表示されます:
- 可用性:この数値は、GitLab.com全体の可用性目標である99.95%のアップタイムと比較することができます。
- 使われた予算: グループが所有する機能が十分に機能していない過去 28 日間の時間。
予算はコンポーネントごとの指標に基づいて計算されます。各コンポーネントは2つの指標を持つことができます:
-
Apdex:オペレーションが適切に行われた割合。
適切に実行される」の閾値はメトリクス・カタログに保存されており、対象のサービスによって異なります。API、Git、WebサービスのPuma(Rails)コンポーネントでは、
rails_requestSLIにオプトインしていない場合、このしきい値は5秒です。このプロジェクトでは、このターゲットを設定できるようにしました。リクエストApdexをカスタマイズするには、RailsリクエストSLIを参照してください。この新しいApdex測定は、オプトインするまでエラー予算の一部にはなりません。
Sidekiqジョブの実行では、しきい値はジョブの緊急度に依存します。現在、緊急度の高いジョブは10秒、その他のジョブは5分です。
ステージグループによっては、より多くのサービスがある場合があります。それらの閾値もメトリクス・カタログにあります。
-
エラー率:エラーが発生したオペレーションの割合。
比率の計算は次のようになります:
\frac {operations\_meeting\_apdex + (total\_operations - operations\_with\_errors)} {total\_apdex\_measurements + total\_operations}予算の使われ方のチェック
ステージグループダッシュボードと エラー予算詳細ダッシュボードの両方に、エラー予算がどこに使われたかを確認するためのパネルが表示されます。ステージグループダッシュボードは常に28日間固定で表示されます。エラー予算詳細ダッシュボードでは、経時的なSLIまで掘り下げることができます。
エラー予算行の下の行は、デフォルトでは折りたたまれています。この行を展開すると、過去28日間に最も違反オペレーションを行ったコンポーネントと違反タイプが表示されます。

左側の最初のパネルには、コンポーネントごとのエラー数が表になっています。その表の最初の行を掘り下げることが、使用された予算に最も大きな影響を与えます。
一般的に、最も予算を費やすコンポーネントはSidekiqかPumaです。中央のパネルでは、異なる違反タイプの意味と、ログを深く掘り下げる方法を説明しています。
右側のパネルは、どのエンドポイントまたはSidekiqジョブがエラーを引き起こしているかを明らかにするKibanaへのリンクを提供します。
どのRailsエンドポイントが遅いかを判断するためにこれらのパネルやログを使用する方法については、購入グループのビデオ「Error Budget Attribution」をご覧ください。
表に表示されているその他のコンポーネントは、メトリクス・カタログに定義されているサービス・レベル・インジケータ(SLI)に由来します。
これらのタイプの障害については、type 列からリンクされているサービス・ダッシュボードへのリンクをたどってください。サービス・ダッシュボードには、予算が費やされた原因となっている SLI 専用の行があり、ログへのリンクとコンポーネントが意味することの説明が記載されています。
例えば、web-pages サービスのserver コンポーネントを参照してください:

特定の機能に合わせたSLIを追加するには、Application SLIを使います。
エラー予算用の Kibana ダッシュボード
詳細な分析には、次のような専用の Kibana ダッシュボードを使用できます:
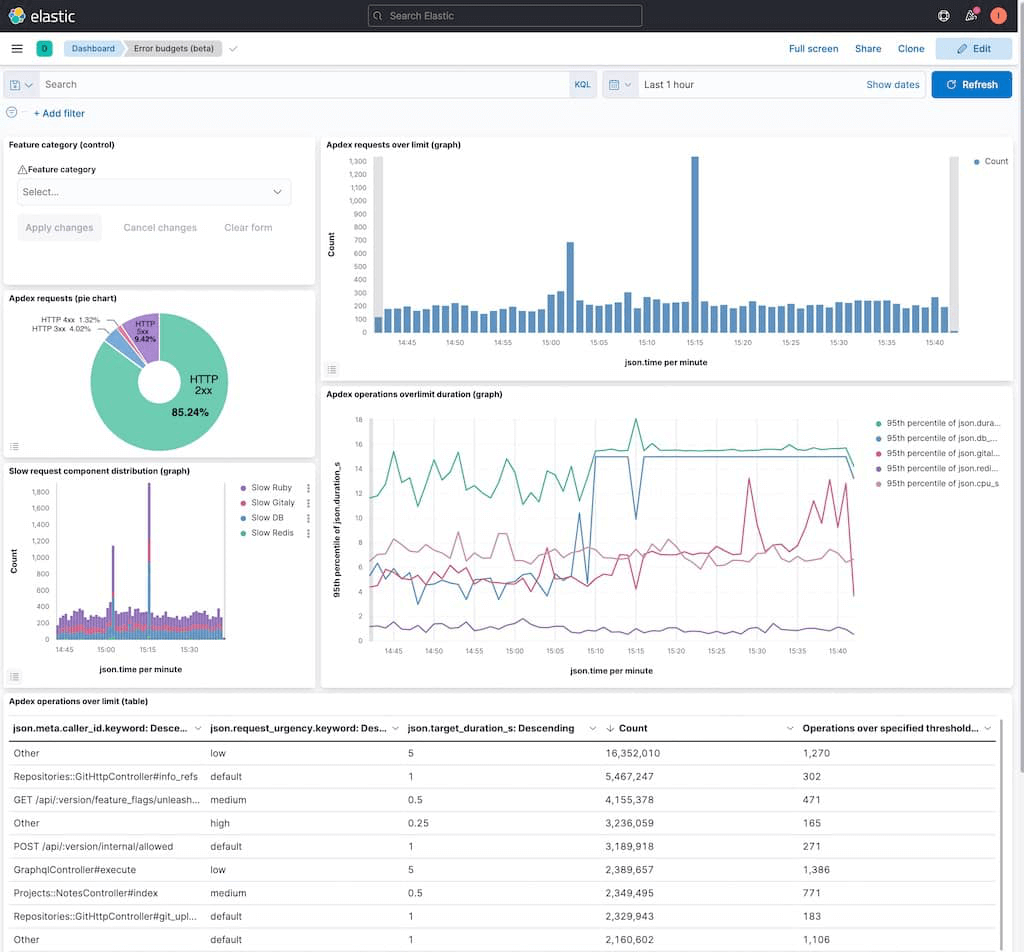
説明
- Apdex requests over limit (graph)- 目標期間を超えたリクエストのみを表示します。
- Apdex operations over-limit duration (graph)- 持続時間コンポーネント(データベース、Redis、Gitaly、Railsアプリ)のディストリビューションを表示します。
-
Apdex リクエスト(円グラフ) -
2xx,3xx,4xx,5xxリクエストの割合を表示します。 - 遅いリクエストコンポーネントのディストリビューション- Apdex 違反の原因となっているコンポーネントをハイライトします。
- 制限を超えた Apdex オペレーション(表) - 各エンドポイントの制限を超えたオペレーション数を表示します。
- Apdex requests overlimit - Apdex 違反の原因となった個々のリクエストのリストを表示します。
ダッシュボードの使用
- 調査したい機能カテゴリーを選択します。
- Feature Categoryセクションまでスクロールします。機能名を入力します。
- 変更を適用] を選択します。選択された結果には、この機能カテゴリに関連するリクエストのみが含まれます。
- 調査期間を選択します。
- ダッシュボードをレビューし、障害の種類に注意します。
答えるべき質問
- 故障パターンはスパイクのように見えますか?それとも持続しますか?
- 障害は特定のコンポーネントに関連していますか?(データベース、Redis、…)
- 障害は特定のエンドポイントに影響しますか?それともシステム全体ですか?
- 障害の原因はインフラ・インシデントですか?